Scheduling scrapy spiders in Jenkins
Kiran Koduru • Oct 4, 2018 • 2 minutes to read
If you haven’t figured how to run cron jobs to schedule your scrapy spiders, then I would suggest checking out my last post. And if you already figured how you would setup your Jenkins instance to run scrapy spiders then you can stop reading now. But if you would like to read up on how to configure your Jenkins job to pull in your scrapy project from github then please keep reading.
Downloading and Installing Jenkins
If you don’t have a fresh installation of jenkins, you can download a version that best suits your OS from jenkins.io. Follow instructions on how to get in up and running on their installation page. I, myself, downloaded a war file which runs from the command line.
$ java -jar jenkins.war Running from: /home/..../jenkins.war webroot: $user.home/.jenkins Oct 01, 2018 12:29:45 AM org.eclipse.jetty.util.log.Log initialized INFO: Logging initialized @739ms to org.eclipse.jetty.util.log.JavaUtilLog Oct 01, 2018 12:29:45 AM winstone.Logger logInternal ... INFO: Listed all plugins
Once we have Jenkins up and running, we can proceed to setting up our scrapy job Jenkins.
Setup Jenkins job
For this blog, I created a sample project which scrapes the first page of books.toscrape.com. We will creating a Jenkins job via a some groovy code. Make sure your Jenkins version has Pipeline plugin installed.
node {
stage('Clone') {
sh "rm -rf *"
git 'https://github.com/kirankoduru/sample-scrapy-spider.git'
}
stage('Setup & Run Scrapy Spider') {
sh """
virtualenv -p python3 venv
. venv/bin/activate
pip install scrapy
. venv/bin/activate
cd sample_project
scrapy crawl test_spider
"""
}
}Setup cronjob
Once you have the job setup, you can configure the job to run once in day. Jenkins allows a nice alias to schedule cron daily using the @ sign.
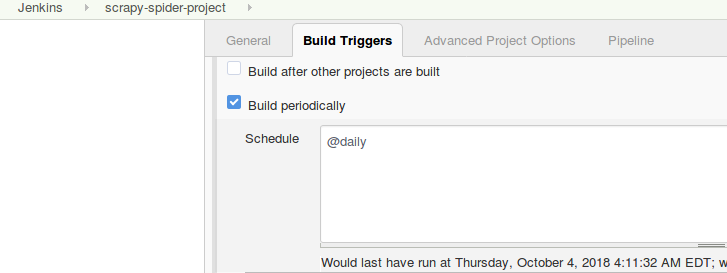
Trigger build remotely
Another perk of using Jenkins is you can hit a curl endpoint to trigger your build remotely. I added a token(sample-scrapy-project-token) to allow building my scrapy project remotely.

To trigger the job I can send a curl request or use an external program that needs new data whenever a user visits your site. Here’s what my sample curl request would look like
$ curl --user admin:admin http://localhost:8080/job/scrapy-spider-project/build?token=sample-scrapy-project-token
You should probably use a better Jenkins username and password than admin:admin and also a token that is random series of alpha-numeric characters.
Conclusion
I would say Jenkins is battle tested and has many use cases. One of them being scheduling jobs. You can get creative and use your Jenkins host to schedule other ETL jobs you might have as well. So go ahead and poke around some more. Maybe you might skip using scrapyd as your scrapy scheduling solution.

I am writing a book!
While I do appreciate you reading my blog posts, I would like to draw your attention to another project of mine. I have slowly begun to write a book on how to build web scrapers with python. I go over topics on how to start with scrapy and end with building large scale automated scraping systems.
If you are looking to build web scrapers at scale or just receiving more anecdotes on python then please signup to the email list below.